
News
Corona-Inzidenzen nach Impfquote, pro Kreis
Diese Daten sind von Anfang Dezember 2021 und damit outdated.
Für die politische Ebene völlig überraschend befinden wir uns in der 4. Coronawelle und haben zum Glück darauf geachtet, noch vor dem Herbst die Impf- und Testkapazitäten zurückzufahren. Das gibt uns die Gelegenheit zu einer interessanten Auswertung: Man errechne die allgegenwärtigen 7-Tage-Corona-Inzidenzen für jeden Land-/Stadtkreis, und halte sie gegen die Quote der Vollgeimpften für jeden Kreis (alle Datenquellen am Ende des Artikels). Es kommt das folgende Bild heraus (Klick zum Vergrößern):
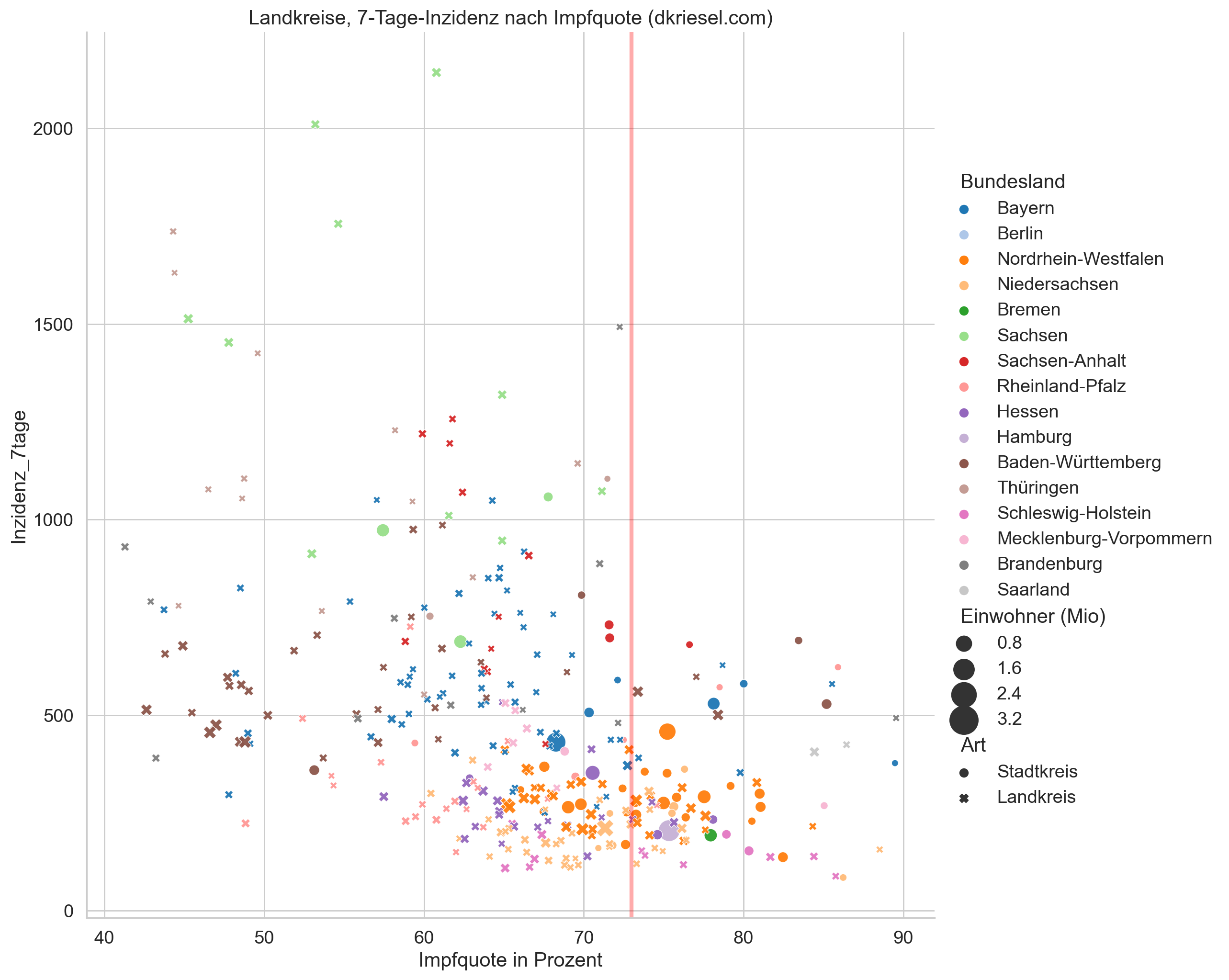
Wie immer erhaltet ihr von mir einen ausführlichen Beipackzettel, der die Ergebnisse und die Unsicherheiten enthält. Ich fange mit den Unsicherheiten an.
Ein kleiner Technologiestack für DataScience-Heimprojekte
 Ich bin jetzt ziemlich weit damit, den Mailhaufen abzuarbeiten, den ich im Nachgang zu meinem BahnMining-Vortrag gekriegt habe. Die mit Abstand am häufigsten gestellte Frage, die mich erreicht hat, war die nach einer kurzen Beschreibung meines Techstacks, bzw. einer verallgemeinerten kurzen Beschreibung, wie man technisch an sowas herangeht. Also gibt es hierfür vorweg mal einen eigenen Blogpost. Ich unterteile die vier Phasen Download, Parsing, Zusammenführung, und zum Schluss die Analyse an sich. Alsdann:
Ich bin jetzt ziemlich weit damit, den Mailhaufen abzuarbeiten, den ich im Nachgang zu meinem BahnMining-Vortrag gekriegt habe. Die mit Abstand am häufigsten gestellte Frage, die mich erreicht hat, war die nach einer kurzen Beschreibung meines Techstacks, bzw. einer verallgemeinerten kurzen Beschreibung, wie man technisch an sowas herangeht. Also gibt es hierfür vorweg mal einen eigenen Blogpost. Ich unterteile die vier Phasen Download, Parsing, Zusammenführung, und zum Schluss die Analyse an sich. Alsdann:
Wahl-O-Mat-Auswertung Bundestagswahl 2017, Teil 2: Thesen- und Parteienverwandtschaften
 Heute geht es noch mal ein bisschen um den Wahl-O-Mat. Wie letztes mal werte ich die Parteien nach ihren Antworten auf die Wahl-O-Mat-Thesen aus, aber diesmal rendere ich daraus keine Landkarte, sondern eine Cluster Heatmap. Diese Art der Grafik ist etwas komplexer. Dafür ist sie sehr Informationstragend. Ich präsentiere sie wieder zuerst, und danach führe ich euch schrittweise heran. Wie immer könnt ihr die Grafik zum Vergrößern klicken.
Heute geht es noch mal ein bisschen um den Wahl-O-Mat. Wie letztes mal werte ich die Parteien nach ihren Antworten auf die Wahl-O-Mat-Thesen aus, aber diesmal rendere ich daraus keine Landkarte, sondern eine Cluster Heatmap. Diese Art der Grafik ist etwas komplexer. Dafür ist sie sehr Informationstragend. Ich präsentiere sie wieder zuerst, und danach führe ich euch schrittweise heran. Wie immer könnt ihr die Grafik zum Vergrößern klicken.
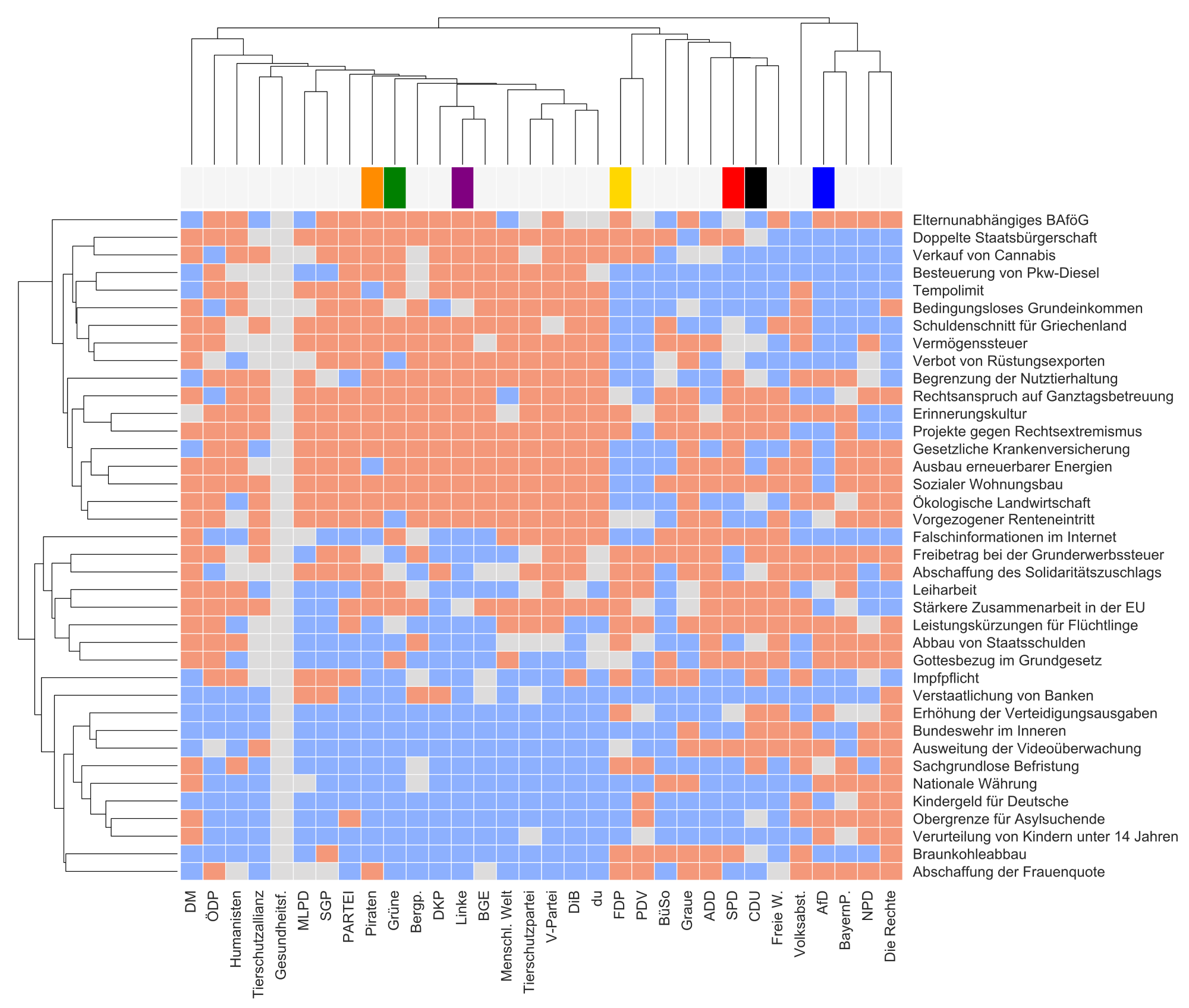
Auswertung des Bundestags-Wahl-O-Mats 2017 zu einer Parteienlandkarte
 Jeder kennt von euch sicherlich den Wahl-O-Mat. Man bekundet seine Zustimmung oder Ablehnung gegenüber verschiedenen Thesen. Das machen auch die Parteien, die sich zur Bundestagswahl stellen. Und daran, wie ähnlich oder unähnlich die eigenen Antworten zu den Antworten der Parteien sind, kriegt man dann Parteien zur Wahl empfohlen.
Jeder kennt von euch sicherlich den Wahl-O-Mat. Man bekundet seine Zustimmung oder Ablehnung gegenüber verschiedenen Thesen. Das machen auch die Parteien, die sich zur Bundestagswahl stellen. Und daran, wie ähnlich oder unähnlich die eigenen Antworten zu den Antworten der Parteien sind, kriegt man dann Parteien zur Wahl empfohlen.
Das ermöglicht aber auch, die Antworten aller Parteien abzusaugen und gegeneinander auszuwerten. Heraus kommt die folgende Landkarte. Ähnliche Parteien sind miteinander verbunden. Je ähnlicher, desto stärker sind sie verbunden, und desto näher liegen sie beieinander.
Und siehe da, die politischen Richtungen von Links nach Rechts haben sich ganz von alleine ungefähr herauskristallisiert (ich musste die Karte nur noch drehen, so dass Links auch Links und Rechts Rechts ist). Siehe hierzu aber auch einen Edit am Schluss.
Ihr könnt den Graph nutzen, um jetzt auch die kleineren Parteien zu verorten, von deren Existenz ihr vielleicht noch gar nichts wusstet. Interessant ist auch, dass man deutlich sieht, wie sich eine sehr stark verbundene, weil sehr homogene Gruppe aus anscheinend linken Parteien herauskristallisiert hat.
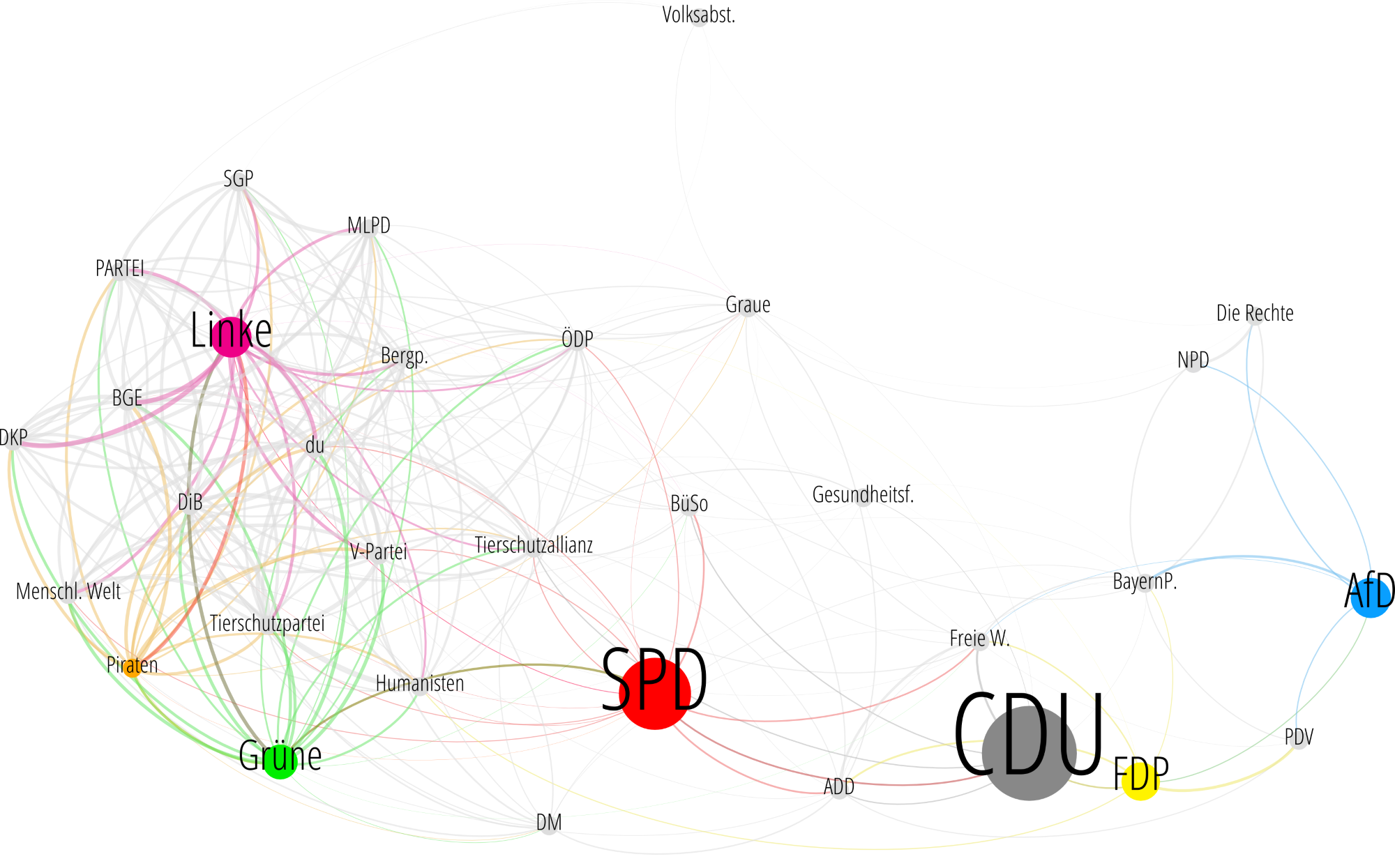
Bild klicken zum Vergrößern. Die Größe der Parteien ist übrigens proportional zu deren Umfragewerten zum Erstellzeitpunkt des Artikels, wobei ich die Kleinstparteien aber hart auf 2% gesetzt habe, damit man die besser sieht.
Im Rest des Artikels findet ihr ein paar Informationen zur Methodik und warum die Landkarte mit Vorsicht zu genießen ist.