
Inhaltsverzeichnis
![]()
SpiegelMining. Auch Spiegelredakteure feiern Weihnachten. Eine Analyse von 70.000 SpiegelOnline-Artikeln
Seit Mitte 2014 habe ich mehr als 70.000 Artikel von SpiegelOnline systematisch gespeichert. Jeden Tag kommen im Schnitt 100 dazu. Diese Artikelmasse werden wir in der nächsten Zeit auswerten und erforschen. Was herauskommt, ist eine tiefgreifende Analyse des Publikationsverhaltens des vielleicht größten Meinungsmachers Deutschlands.
Ich werde über die nächste Zeit in einer losen Blogartikel-Serie unter dem Namen SpiegelMining etwas greifbarer machen, wie SpiegelOnline funktioniert. Geplant ist ein SpiegelMining-Artikel alle zwei bis drei Wochen, bitte seid mir aber nicht böse, wenn das leicht variiert. Vielleicht finden wir sogar ein paar Sachen heraus, bei denen auch die Kollegen von SpiegelOnline zugeben müssen: „krass, das war nicht mal uns selbst so klar“. Zusätzlich werde ich verschiedene Methoden des Daten-Auswertens anhand des SpiegelOnline-Datensatzes plausibel, anschaulich und interessant machen – und zwar auch für Nicht-Informatiker.
Bei einigen der Auswertungen wird vielleicht „nur“ das rauskommen, was man sich schon vorher denken konnte. Bei anderen werden wir überraschende Ergebnisse erhalten. Und manchmal entdeckt man auch Systematiken da, wo man vielleicht überhaupt keine erwartet hat – ein Beispiel dafür findet sich schon in diesem Blogartikel.
Wie funktioniert das Ganze?
Einer meiner Server guckt seit Mitte 2014 in kurzen Zeitabständen nach, ob auf SpiegelOnline irgendwelche neuen Artikel sind. Wenn neue da sind, werden sie heruntergeladen und in einer Datenbank gespeichert. Die Auswertungen hier passieren also nur auf frischen Artikeln. Darum sind es auch nur „so wenig“  (hätte ich es darauf angelegt, alle alten Artikel herunterzuladen, wäre der Datensatz größer).
(hätte ich es darauf angelegt, alle alten Artikel herunterzuladen, wäre der Datensatz größer).
Auf dieser wachsenden Datenbank von Artikeln arbeite ich und analysiere Merkmale von den Artikeln. Merkmale eines Artikels sind zum Beispiel das Veröffentlichungsdatum, die Rubrik, in der der Artikel veröffentlicht wurde, oder auch die Anzahl der Worte, die der Artikel enthält. Viele, viele weitere Merkmale sind natürlich denkbar, und wir werden im Laufe der Zeit auch noch weitere kennenlernen und hier auswerten. Die jetzt genannten sind offensichtliche für den Anfang, damit ich als Schreiberling und ihr als Leser erstmal reinkommt. Man darf überrascht sein, was man da schon alles rauslesen kann. Da ich die Artikel in Rohform gespeichert habe, kann ich alle möglichen Merkmale auch noch im Nachhinein für alle heruntergeladenen Artikel auslesen – daher: schickt mir auch gerne noch weitere Ideen! Simpel, kreativ, politisch inkorrekt: Alles wird beachtet, wenn ich es zeitlich und technisch schaffe.
Wir tasten uns im Rest dieses Artikels an den Datensatz und verschiedene Visualisierungen heran. Wir werden uns kleinschrittig von grober zu feiner Granularität vorarbeiten um auch Leser, die keine Informatiker sind, mit auf die Reise nehmen zu können. Als ganz grundlegendes Merkmal betrachten wir erst einmal die Veröffentlichungszeiten aller Artikel – und später lernen wir zusätzlich die Rubriken von SpiegelOnline kennen und danach versuchen wir, ein System hinter der Länge der Artikel zu ergründen.
Die ersten Gehversuche: Wir spielen mit dem Veröffentlichungsdatum
Erstmal ein paar ganz grundlegende Beobachtungen:
- Die Datenbank startet am ersten Juli 2014
- Der für diesen Artikel verwendete Datensatz geht bis 17. April 2016.
- In dieser Zeitspanne wurden 63312 Artikel heruntergeladen
Das bedeutet, dass SpOn so um die 100 Artikel am Tag veröffentlicht. Das ist schon einiges.
Warum endet der Datensatz für diesen Artikel schon am 17. April? Ich hatte den Artikel etwas auf Halde, um erstmal bei mir intern gucken zu können, wie sich die Sache entwickelt. Ich habe aber alle Ergebnisse und Graphiken noch mal mit den Werten von heute verglichen. Es hat sich nichts grundlegendes an den Ergebnissen verändert, also rendere ich jetzt nicht noch mal alle Grafiken neu.
Wie oben schon gesagt: Visualisierung ist enorm wichtig, um Daten zu verstehen.Wir nehmen jetzt also von jedem Artikel das Merkmal „Veröffentlichungsdatum“ und visualisieren, wie viele Artikel auf SpOn an jedem betrachteten Tag veröffentlicht wurden:
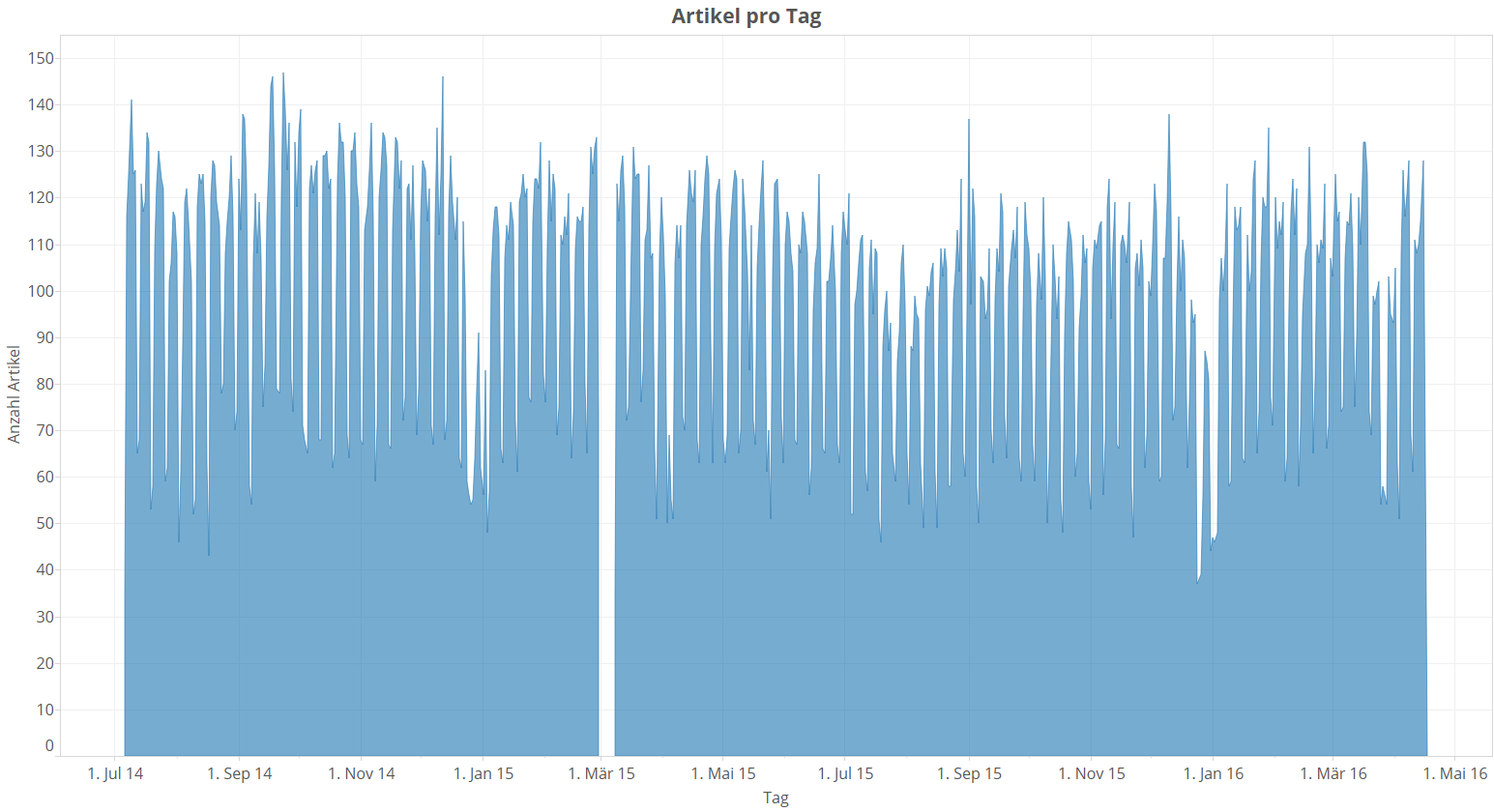
Wenn ihr auf Grafiken in diesem Artikel klickt, werden diese vergrößert.
Als erstes fallen die sehr regelmäßigen lokalen Schwankungen ins Auge: Es sieht so aus, als ob SpOn am Wochenende viel weniger Artikel veröffentlicht als in der Woche – wir verifizieren das gleich noch. Dann sieht man über die Jahreswechsel hinweg starke Einbrüche in der Artikelanzahl. Auch SpOnredakteure feiern offensichtlich Weihnachten und Silvester und haben die Tage dazwischen ganz gerne mal frei – so viel, so erwartbar. Und ich bringe diesen Plot auch deshalb zuerst, weil ich eine kleine Beichte zu machen habe: Beachtet den krassen Einbruch auf Null Anfang März 2015. Aufgrund eines Bugs ist mein Downloader hier mehrere Tage ausgefallen. Im Vergleich zum Gesamtdatensatz ist die verlorene Datenmenge jedoch gering.
Wir wollten noch verifizieren, dass die regelmäßigen Schwankungen wirklich die Wochenenden sind. Das machen wir, in dem wir die Artikel pro Veröffentlichungs-Wochentag zählen:
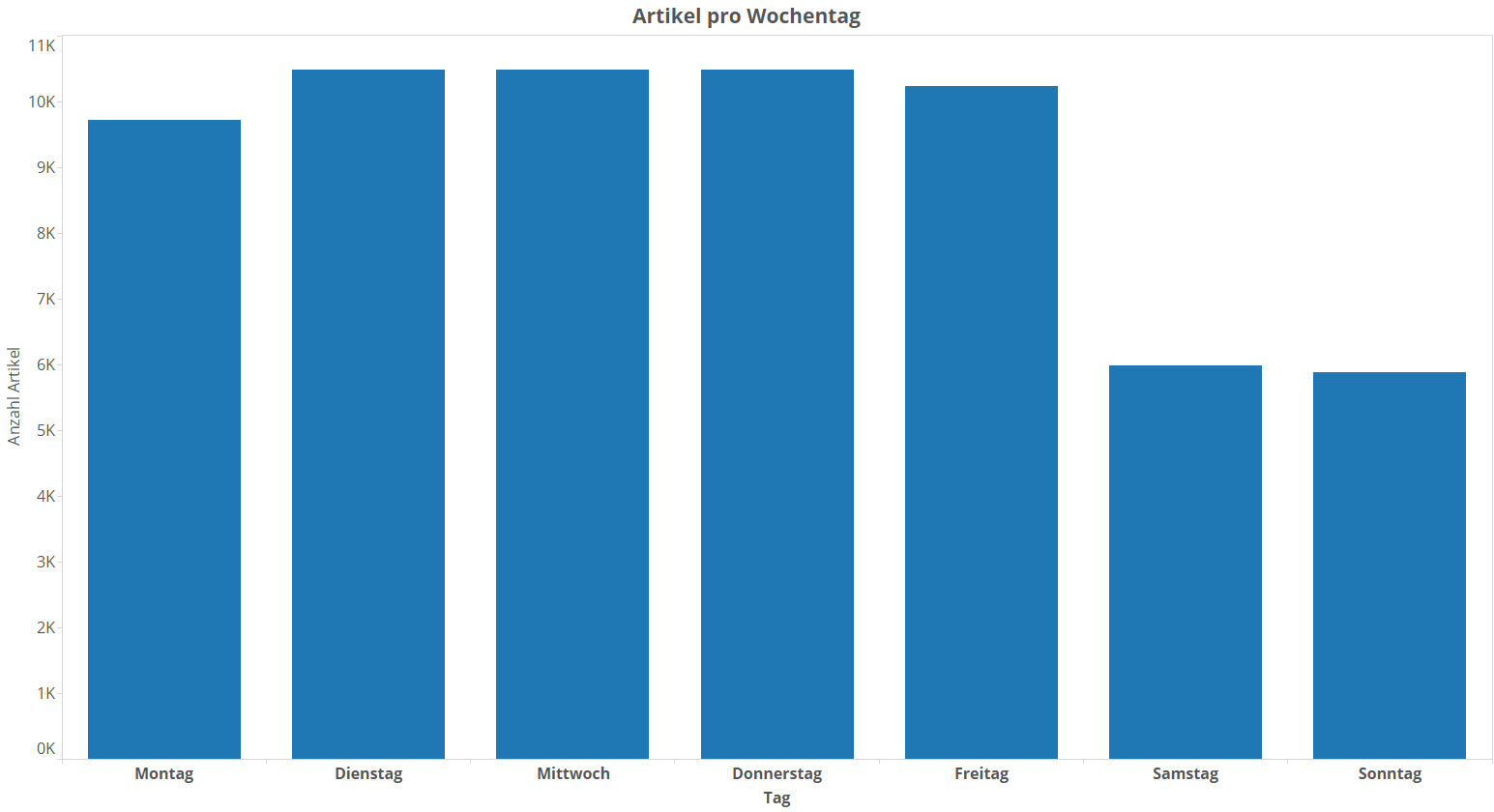
Siehe da – an den Samstagen und Sonntagen wurden in der Tat nur etwas mehr als halb so viele Artikel veröffentlicht wie an den Wochentagen. Man sieht auch deutlich ein leichtes Montagstief. Auch SpOn-Redakteure sind Menschen.
Jetzt, wo wir die Ursache der regelmäßigen Schwankungen kennen, können wir die Schwankungen für eine einfachere Betrachtung auch mal rausfiltern. Wir zählen wiederum die Artikel über die Zeit, aber diesmal pro Kalenderwoche:
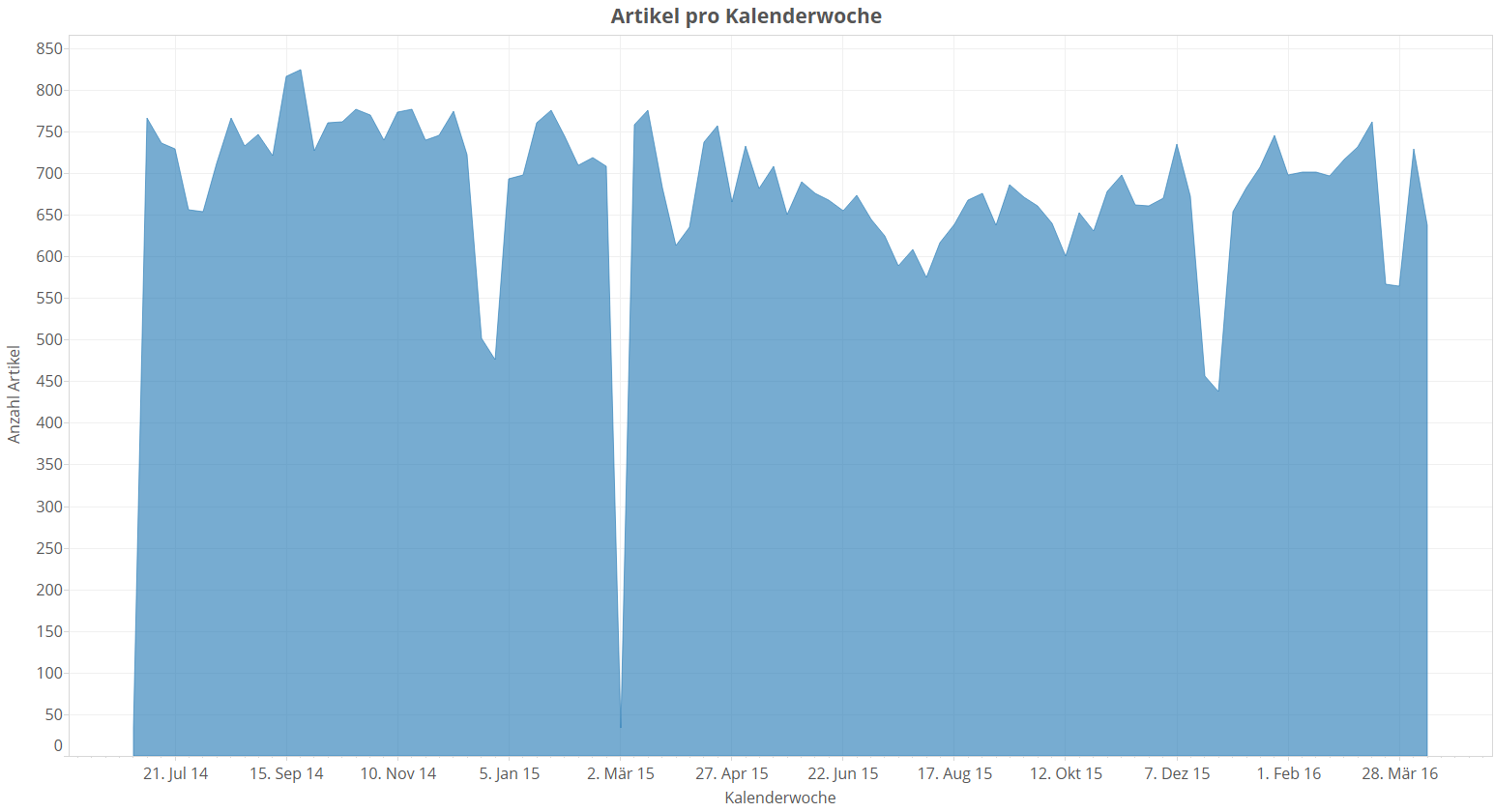
Zack, die hochfrequenten Schwankungen sind weg. Schon übersichtlicher, oder? Das ist in der Praxis oft so. Viele Datensätze haben Wochenendschwankungen. Für Langzeitbetrachtungen ist es manchmal sinnvoll, sie herauszufiltern. Durch die kalenderwochenweise Betrachtung werden wir auch einen guten Teil des sonstigen Grundrauschens los. Was man immer noch deutlich sieht, sind die Jahresend-Einbrüche und meine Downloadpause im März 2015. Wie erwartet, schwankt die Anzahl der Artikel um die 700 Artikel pro Woche.
Wo wir schon dabei sind, können wir die Artikelveröffentlichungen auch mal nach Tageszeit (d.h. Stunde) zählen:
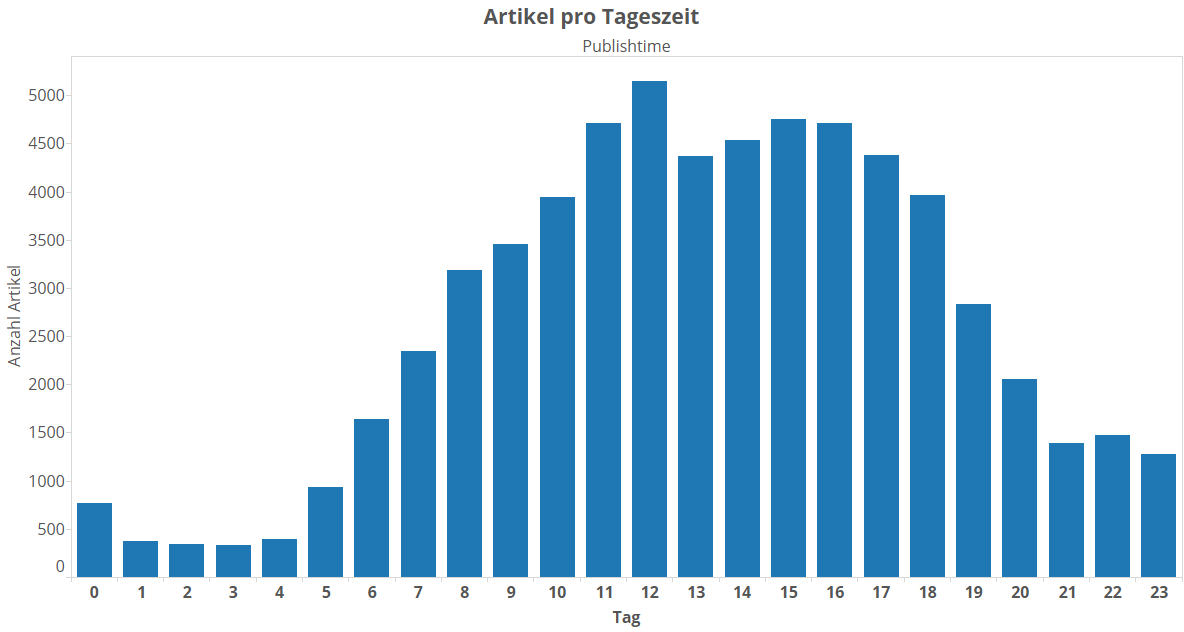
Ich würde mal sagen, der Einbruch um 13 Uhr bedeutet, dass dort ein Großteil der SpOn-Redakteure Mittagspause macht. Wie könnte man denn vorgehen, wenn man nun das Artikelaufkommen nach Tageszeiten und Wochentagen visualisieren will? Man könnte genau so einen Balkenplot machen wie wir das oben zu den Wochentagen und Stunden schon gemacht haben – nur mit 24 * 7 = 168 Balken:
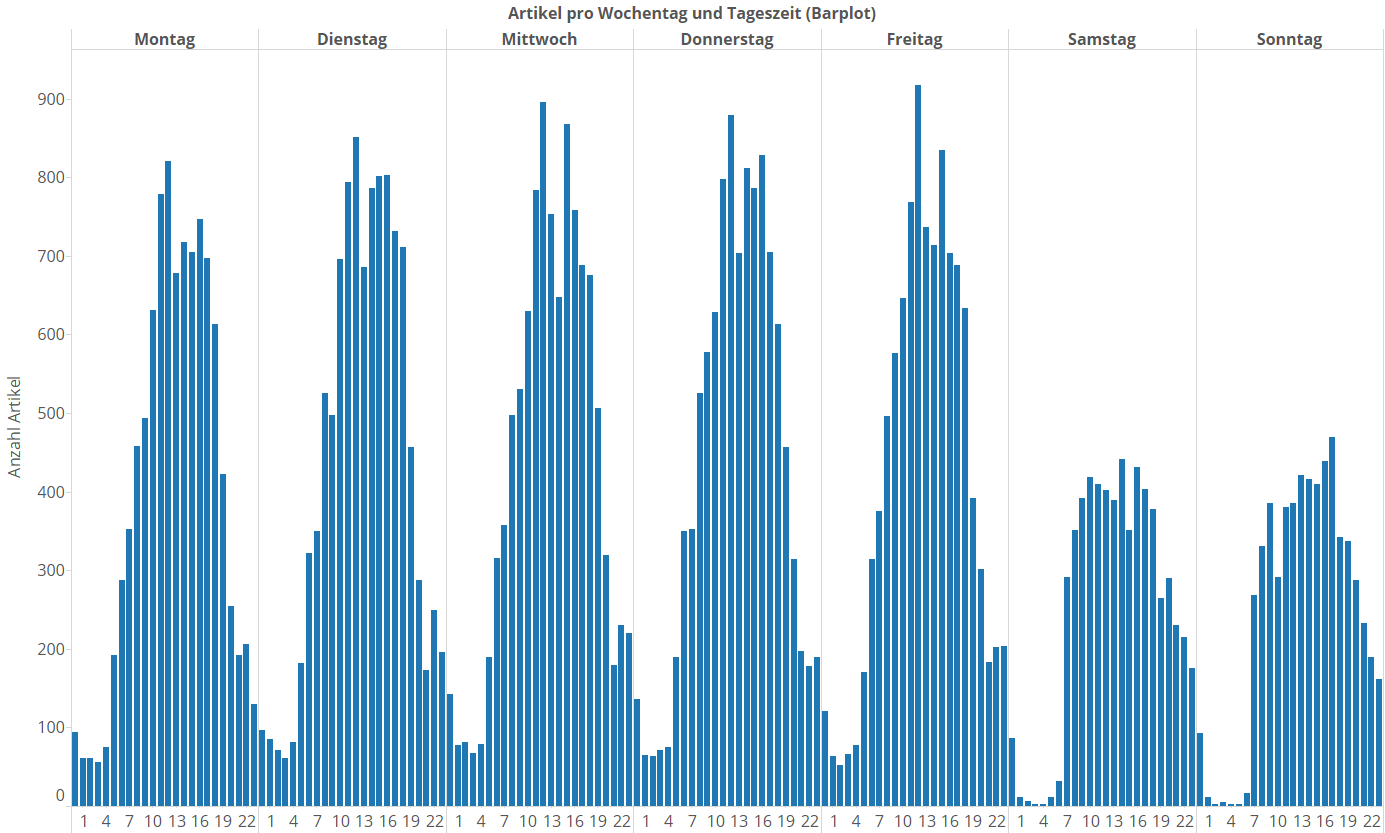
Man sieht wieder deutlich, wie am Wochenende weniger publiziert wird. Auch die Täler vor den Wochenendtagen sind tiefer. Diese Darstellung hat Vorteile und Nachteile. Der Vorteil ist, dass man für jeden Balken relativ exakt anhand der Y-Achse seine genaue Höhe (=Artikelanzahl) bestimmen kann. Oftmals braucht man das aber gar nicht so exakt. In der Regel geht es ja nicht darum, ob jetzt Freitags von 12 bis 13 Uhr im Betrachtungszeitraum exakt 917 oder 930 Artikel veröffentlicht wurden, sondern man gibt für eine Visualisierung häufig gerne etwas Genauigkeit her, wenn man dafür die Tendenzen und Relationen besser erfassen kann. Wir wechseln nun also die Darstellungsweise zu einer sogenannten Heatmap:
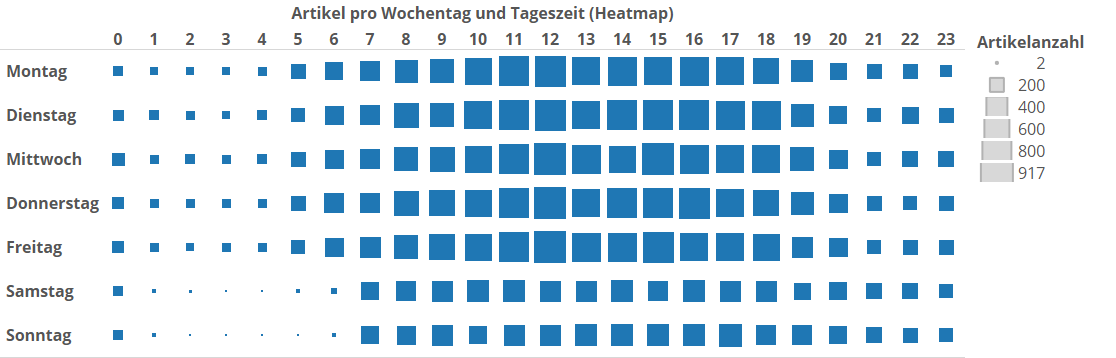
Das sind dieselben Daten wie im vorherigen Bild, nur anders aufgetragen. Das ganze Diagramm ist nun eine Art Tabelle. Auf der Y-Achse sind die Wochentage, und auf der X-Achse die Tageszeitstunden aufgetragen. Das, was vorher die Balkenhöhe war, wird nun durch die Größe der Datenpunkte in der Tabelle wiedergegeben. In dieser Darstellung können wir weniger exakt sehen, ob ein Datenpunkt jetzt 917 oder 930 Artikel groß ist. Im Austausch dafür können wir aber wesentlich besser Zusammenhänge zwischen den Wochentagen und Tageszeiten erkennen, und die sind oftmals viel mehr unser Ziel! (Für die erfahreneren Leser: Es hat einen Grund, warum ich nicht die Farbe der Datenpunkte für die Visualisierung der Artikelanzahl nehme, auch wenn das leicht eingängiger gewesen wäre; die Farbe brauche ich nämlich später noch und sie soll dann unbelastet sein.)
Im Plot sieht man, dass man das Veröffentlichungsverhalten von SpiegelOnline eigentlich mit folgendem Satz beschreiben kann: „Die meisten Artikel werden genau in der Kernarbeitszeit veröffentlicht.“ Die Wochentags sehr artikelreichen Stunden von 10 bis 19 Uhr fallen an den Wochenenden nur halb so stark aus. Abends ist das Niveau über die Woche ungefähr gleich. Und in den frühen Morgenstunden von Samstag und Sonntag wird fast nichts veröffentlicht, was ich den Kollegen bei SpOn nicht verdenken kann.
Das wirkt auf den ersten Blick zwar völlig erwartbar, man sieht daran aber, dass sich der Spiegel von seinem zeitlichen Veröffentlichungsverhalten her noch als traditionelles Offlinemedium sieht. Wie sieht denn im Vergleich das Veröffentlichungsmuster eines Mediums aus, was sich komplett online sieht? Nehmen wir als Beispiel Buzzfeed.
Ein Blick über den Tellerrand zu Buzzfeed
Buzzfeed ist nach eigener Aussage „Das Medienunternehmen für das soziale Zeitalter“ (gemeint ist die Verbreitung der sozialen Netze). Ich zitiere Wikipedia: In seiner Anfangszeit präsentierte BuzzFeed fast ausschließlich unterhaltende, schnell konsumierbare Inhalte, die darauf ausgelegt waren, möglichst direkt in sozialen Netzwerken verbreitet (geteilt) zu werden. Typisch dafür waren Katzenvideos.
Etwas weniger akademisch ausgedrückt ist Buzzfeed also so etwas wie das Dixiklo des Internets, nur darauf ausgelegt mit Clickbaits, Bullshit und user generated „content“ schnelle Kohle zu machen. Ein bisschen wie die Bildzeitung, wenn man die Nachrichten rausstreicht und den Platz mit dem Bild-Mädchen oben ohne auffüllt.
Das Resultat fällt aus wie unter diesen Voraussetzungen erwartbar: Buzzfeed hat beachtliche Zugriffszahlen und Hundert Millionen Dollar Umsatz in 2014. 
Für so ein Medium ist es natürlich essentiell, mit seinen Veröffentlichungsstrategien diejenigen Zeiträume extrem zu bevorzugen, in denen seine Nutzer auch Zeit haben. Wenn die Benutzer draufgucken, soll bitteschön auch ein neuer Artikel a la „18 ergreifende Katzenbilder!! Nummer 14 wird dich umhauen!“ zu sehen sein. Und bitte nur dann, alles andere ist Aufwand und bringt nichts.
Darum geht Buzzfeeds Veröffentlichungsstrategie deutlich gezielter zur Sache als die von SpiegelOnline. Cosmin Cabulea hat mal eine kleine Auswertung vier Wochen Buzzfeed gemacht und stellt in seinem Blogartikel dar, dass Buzzfeed genau außerhalb der Kernarbeitszeiten veröffentlicht, also sozusagen wie SpiegelOnline, nur genau andersrum. Veröffentlicht wird durch die Nacht hindurch, die meisten Veröffentlichungen geschehen zum Feierabend, und es gibt sogar einen klar abgegrenzten Veröffentlichungspeak zur Mittagszeit (wir erinnern uns, dass es hier bei SpiegelOnline einen kleinen Einbruch gibt). Am Wochenende passiert allerdings auch auf Buzzfeed weniger als sonst.
Ich könnte mir vorstellen, dass das Besucherverhalten bei SpiegelOnline ähnlich ist. Auch SpiegelOnline lesen Arbeitnehmer sicher vorwiegend in der Mittagspause und im Feierabend. Mich wundert daher, dass bei SpiegelOnline keine solche Veröffentlichungsstrategie an den Artikelverteilungen über die Woche ersichtlich wird, ich hätte das beim wichtigsten Onlinemedium Deutschlands anders erwartet. Na, vielleicht finden wir ja noch andere Anzeichen für Strategien.
Wir haben jetzt ein einzelnes Artikelmerkmal, den Veröffentlichungszeitpunkt, einmal durchgeknetet und aus verschiedenen Aspekten heraus betrachtet – von sehr grober Ebene bis hinunter auf die Ebene kleiner Artikelgruppen. Wir sind nun weit genug, um weitere Merkmale betrachten (Informatisch: „den Merkmalsraum erweitern“) zu können und noch tiefer einzusteigen.
Nächstes Merkmal: Rubriken von Artikeln
Wie andere Medien auch sortiert SpOn seine Artikel in Rubriken ein. Manche Rubriken sind umfangreicher, manche kleiner.
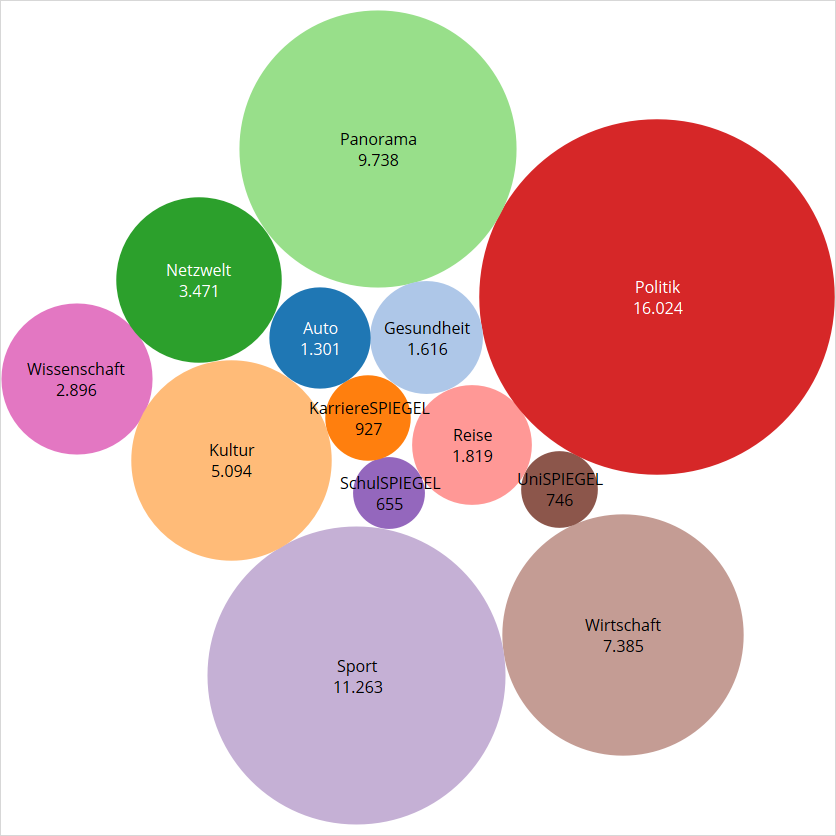
Diese Darstellungnsform heißt packed bubbles – die Flächeninhalte der Kreise korrespondieren zur Anzahl der Artikel der jeweiligen Rubrik. So kann man auf einen Blick sehen, wer eher groß und eher klein ist. Die SpiegelOnline-Medienlandschaft wird ganz klar dominiert von den Rubriken Politik, Sport und Panorama. Zusätzlich sind die Kreise eingefärbt. Das ist eigentlich gar nicht notwendig, weil uns die Farben hier keine weitere Information liefern. Es ist aber ganz praktisch, um Leser schon einmal an die Farben zu gewöhnen, wenn man sie später verwenden will. Das machen wir jetzt: Wir färben den Kalenderwochen-Plot, den wir oben schon gesehen haben, nach Rubriken ein. Vielleicht erkennen wir ja irgendwelche Tendenzen.
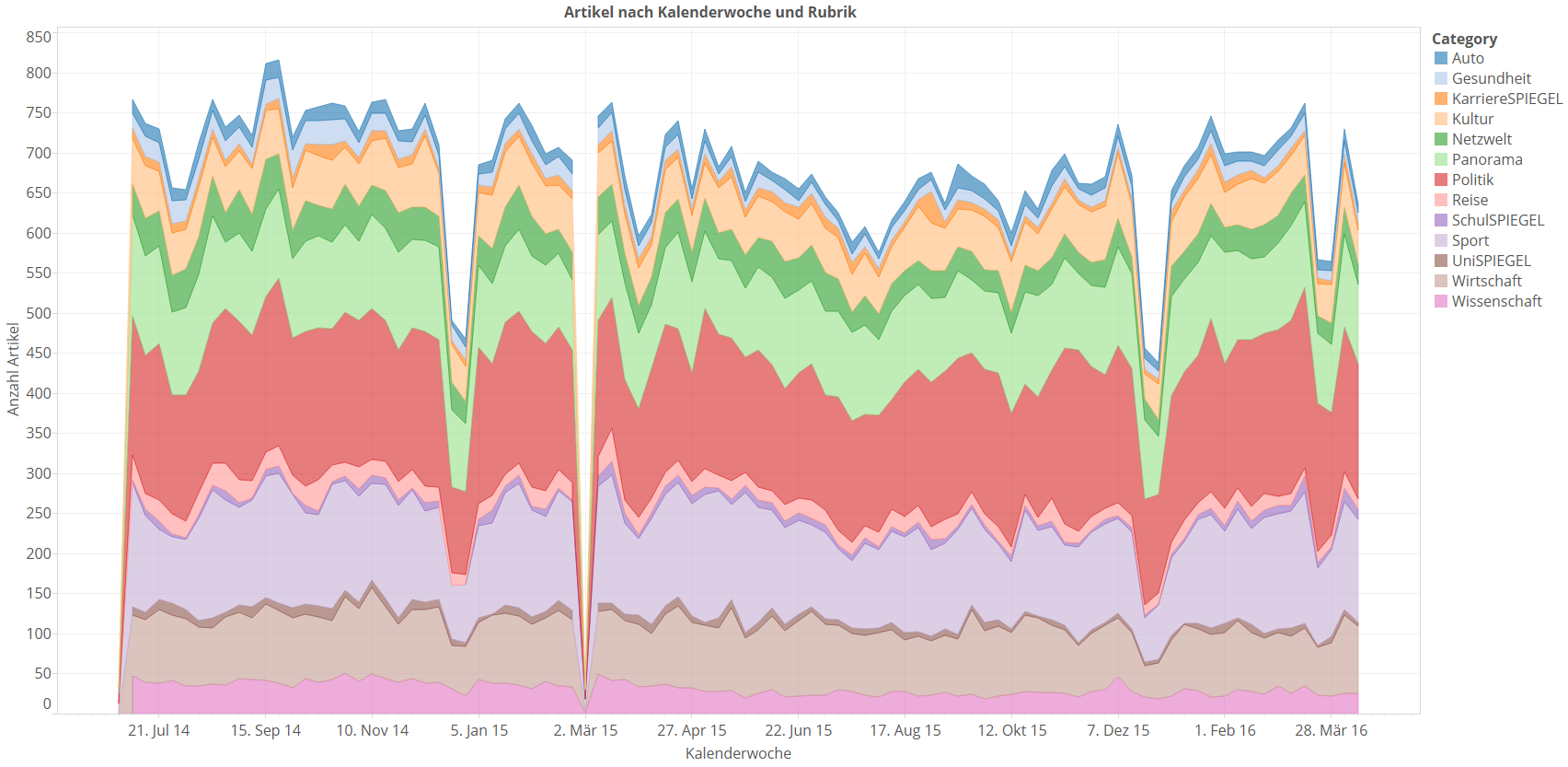
– „Wie Sie sehen, sehen Sie nichts.“ Alles sehr unübersichtlich, allenfalls mit Mühe kann man was erkennen, denn je weiter oben eine Rubrik steht, umso mehr Störungen schleppt sie von den darunterliegenden Rubriken mit. Ich bilde mir zum Beispiel ein, dass die Rubrik UniSPIEGEL in letzter Zeit weniger veröffentlicht. Aber sicher bin ich mir nicht. Um die Veränderung der Rubrikstärken über die Zeit gut beobachten zu können, vergröbern wir die Granularität auf Monate und widmen jeder einzelnen Rubrik einen eigenen Plot mit Trendlinie. Long Story short: Die Veröffentlichungszahlen von SpOn sinken in vielen Rubriken leicht, aber nicht in den drei großen, so dass man es in den Gesamtveröffentlichungsplots kaum wahrnimmt. Manche Rubriken schrumpfen allerdings mehr. Hier ein paar ausgewählte:

Panorama und Politik sind eher wenig von der Schrumpfkur betroffen, Wissenschaft und UniSPIEGEL eher mehr (ob die vielbeachtete Berichterstattung dieses Blogs zu einem Artikel des Unispiegels 2012 dazu beigetragen hat, konnte nicht in Erfahrung gebracht werden. Unsere obige Vermutung bezüglich des Unispiegels war also korrekt. Gesundheit, Netzwelt und Reise sinken auch stark.
Textlänge von Artikeln
Jetzt haben wir ein Gefühl für die Rubriken und deren Wichtigkeit für den Spiegel. Nehmen wir ein weiteres Merkmal hinzu: Die Textlänge, also die Anzahl der Worte in einem Artikel. Wir nehmen hier Medianwerte anstatt von Durchschnittswerten, weil Mediane weniger von irgendwelchen Ausreißern ruiniert werden können. Salopp gesagt: Man findet die Median-Textlänge, indem man alle Artikel nach Textlänge ordnet, und sich danach die Textlänge rauspickt, die genau in der Mitte liegt. Über alle Spiegelartikel in der Datenbank hinweg liegt die Median-Textlänge bei 358 Wörtern. Damit ihr ein Gefühl kriegt: Das ist dann so ein Standard-SpiegelOnline-Artikel wie der hier. Acht Absätze inklusive Teaser. Gar nicht mal sooo lang. Hat man in zwei Minuten überflogen. Interessanterweise weichen die Median-Textlängen der einzelnen Rubriken aber teilweise deutlich vom Gesamt-Median ab:

Im Plot kann man sehen, welche Rubriken eher kurz abgehandelt werden, und welche eher lange Texte haben. Zur Orientierung ist in den Plot eine Linie mit dem Gesamtmedian eingebaut. Panorama ist die Spiegelrubrik für „gemischte Neuigkeiten“. Die Texte scheinen dort eher kurz auszufallen. Bei Sport ebenfalls. Politik ist genau auf dem Gesamtmedian, hat also bei Gesamtbetrachtung ungefähr die „Standardlänge“. Spitzenreiter in den Textlängen sind Gesundheits-Artikel und Kultur (böse Zungen könnten behaupten: Die werden nur von Rentnern gelesen, und die haben Zeit ).
Spaß beiseite: SpiegelOnline vermisst seine Leser, genau wie wir SpiegelOnline gerade vermessen. Jeder Klick von euch füllt die Statistik. Wenn sie so vorgehen, wie ich denke, werden sie genau sehen, welche Artikellängen welcher Rubrik wann gut ankommen und gelesen werden.
Der Gesamt-Median liegt übrigens so tief, weil Sport, Politik und Panorama ja die volumenstärksten Rubriken sind. Und eine Zusatzbemerkung: Das ganze könnte ganz anders aussehen, wenn man feiner aufschlüsselt! Wenn man das irgendwann nach einzelnen Themen schafft, finden sich vielleicht auch unter den kurzen Panoramaartikeln bestimmte Themen, die sehr lang behandelt werden – wer weiß, vielleicht machen wir das ja in einem späteren Artikel. 8-)Und jetzt machen wir mal ein Experiment. Wir betrachten jetzt Merkmale zusammen, hinter denen man gar keinen Zusammenhang vermuten würde.
Merkmale kombinieren: Textlänge und Zeit
Wenn man Textlänge und Zeit zusammen betrachten will, denkt man als erstes daran, zu gucken, ob es vielleicht beim Spiegel eine Kürzungsakttion gegeben hat und der Median oder Durchschnitt der Artikel vielleicht irgendwann sprunghaft weniger geworden sind. Dem ist nicht so, und darum bringe ich den Plot „Textlänge über die Zeit“ hier gar nicht erst.
Erinnern wir uns aber mal an die Heatmap, auf der wir weiter oben aufgetragen haben, wieviele Artikel es pro Wochentag und Tagesstunde gibt. Ihr braucht nicht hochscrollen, hier ist sie nochmal:
Das schöne an DataScience ist immer, wenn man einen Zusammenhang findet, an den man überhaupt nicht gedacht hat. Würdet ihr zum Beispiel denken, dass es einen klaren Zusammenhang gibt zwischen der Textlänge eines Artikels und der Tageszeit, zu der er veröffentlicht wurde? Wie sich rausstellt: Den gibt es. Ich verwende nun die Heatmap wieder, aber habe die Blöcke eingefärbt, und zwar nach deren Textlängen-Median. Für mich überraschenderweise ergibt sich ein sehr klares Muster:
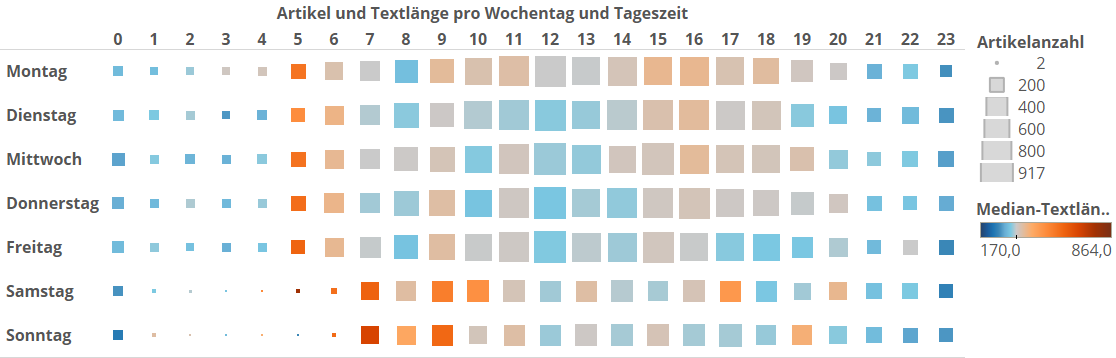
Bei roten Blöcken sind die Textlängen tendenziell länger als über die über den ganzen Datensatz üblich – bei blauen ist es umgekehrt, sie enthalten tendenziell Texte, die kürzer sind als „die Standardtextlänge“. Tieferes rot bedeutet mehr Worte als leichteres rot, das gleiche gilt wieder für Blau. Aus der Grafik geht ein klares Muster hervor: In der Woche werden frühmorgens zwischen 5 und 6 Uhr im Schnitt die längsten Artikel veröffentlicht (vertikale Linie mit roten Blöcken). Danach, also Wochentags über den Tag hinweg, kommen zwar viel, viel mehr Artikel heraus, diese sind aber deutlich kürzer. Am Wochenende bietet sich das gleiche Bild, nur gibt es hier die langen Artikel zwischen 7 und 9 Uhr, der Zeitraum ist also eher gestreckt und auch später (wir hatten oben schon gemutmaßt, dass auch SpiegelOnline-Redakteure am Wochenende mal ausgehen).
Ich hatte oben schon erwähnt, dass wir uns einer Sache sicher sein können: SpiegelOnline vermisst seine Leser genauso, wie ich gerade SpiegelOnline vermesse. Die wissen genau, welche Artikellängen wann gut ankommen. Morgens haben die Leser wahrscheinlich mehr Muße auf lange und aufwändigere Artikel mit mehr Hintergründen, während den Rest des Tages anscheinend kürzere Artikel besser ankommen (der geneigte Spiegelleser muss ja auch noch arbeiten).
Nach der Diskussion mit mehreren Freunden nehme ich zusätzlich an, dass das redaktionsorganisatorische Gründe hat. Morgens werden eben die Artikel veröffentlicht, die über den letzten Tag länger vorbereitet worden sind, dafür ist über den Tag hinweg eben weniger Zeit für Ausführliches, da wird mehr kurz über das Streugut berichtet. Gleichzeitig sind diese arbeitsintensiven (=teuren) Artikel möglichst lange verfügbar, und können auch von den Frühaufstehern gelesen werden (bei vielen Arbeitnehmern geht ja bekanntlich als erste Amtshandlung am Arbeitsplatz erst einmal Facebook und SpOn auf).
Interessant ist aber auch, wie sich dieses Muster über verschiedene Rubriken hinweg verändert. Wir picken mal ein paar heraus. Das nutzen wir natürlich – der Geschichte dieses Blogs eingedenk – um unsere härtesten Vorurteile gegenüber verschiedenen Fachrichtungen und Menschentypen zu zementieren . In dieser Hinsicht drängt es sich geradezu auf, den Kulturteil zuallererst zu behandeln.

In der Kultur ist fast alles im roten Bereich, mit anderen Worten: Die Artikel sind eher lang. Das wussten wir ja schon. Viel interessanter aber: Hier kommen die längsten Artikel nicht um 5 Uhr Morgens, sondern zwischen 10 und 11 Uhr Vormittags (Dunkelroter vertikaler Balken). Der geneigte Kulturwissenschaftler beliebt nun eben etwas länger zu ruhen.
Während bei der Allgemeinbetrachtung erst eher wenige, jedoch lange Artikel veröffentlicht werden, und dann viele aber kurze, ist das im Kulturteil anders: Der Zeitraum mit den längsten Artikeln ist auch gleichzeitig der mit den meisten. Unterdurchschnittlich lange Artikel gibt es höchstens zu nachtschlafender Zeit. Wir machen weiter mit der Politik:

Es gibt wieder die schon aus dem Gesamtbild bekannten „Zonen der langen Artikel“, wobei es hier mehr lange Artikel Nachmittags gibt. An die „Zone der langen Artikel“ Morgens in der Woche schließen sich allerdings viele extrem kurze Artikel an (die dunkeblaue vertikale Reihe). Das fand ich so signifikant, dass ich mal reingeguckt habe. Stellt sich raus, dass hier regelmäßig die Liste der Journalisten veröffentlicht wird, die in der Türkei noch frei rumlaufen dürfen überproportional eine spezielle Art von Artikeln der Art „DerMorgen@SPIEGELONLINE“ erscheint. Beispiel hier. Das ist eine Art Liveberichterstattung. Die wird in Echtzeit erweitert. Wenn der Artikel erscheint, ist er noch fast leer (und wird dann von meinem Server abgerufen, was die kurze gemessene Textlänge erklärt) – und über die nächsten Stunden wird er immer länger. Gehen wir weiter zum Sport:

Lange Artikel gibt es zum einen Wochenend-morgens – das entspricht wieder dem bereits bekannten SpOn-Veröffentlichungsmuster. Ansonsten sind die Artikel insgesamt kurz. Auch das wussten wir bereits von oben. Ich bin sicher, dass SpiegelOnline uns damit sagen will, dass der durschnittliche Sportteilleser eben keine Texte mit mehr als ein paar Absätzen mag . Aber: Es gibt Ausnahmen in Form von ein paar klar ausgezeichneten roten Punkten. Was ist da passiert? Na, das ist doch klar: Wenn eine Sache dem deutschen Leser beim Sport ein paar Absätze lesen mehr wert ist, ist es natürlich – der Fußball.
- Dienstags und Mittwochs um 22 Uhr erscheinen viele Champions-League-Spielberichte. Die sind besonders lang und sorgen deswegen für die rote Farbe. Die Zeiten sind auch relativ genau zwei Stunden nach den üblichen Anstoßzeiten.
- Freitag um 22h sind es Spielberichte der 1. Fußballbundesliga, davor um 20h die der 2. Liga.
- Samstag um 17 Uhr ist es wieder die 1. Liga, die die rote Farbe erzeugt, und um 20h ebenso. Um 22h sind die langen Artikel schon wieder die zur 1. Fußballbundesliga. Soviel erste Liga an einem Tag?!
- Sonntag 19 Uhr: Wieder 1. Liga.
Auch das ist DataScience: Aus Datensätzen Dinge rauslesen, für die sie nie gedacht waren. Wir haben gerade mit einiger Sicherheit die Anstoßzeiten im Fußball aus dem Spiegeldatensatz rausgeholt – einfach anhand der Textlänge der Artikel.
Falls sich übrigens meine Berichterstattung zum Fußball für euch naiv anhört – ich bin überhaupt kein Fußballfan, nie gewesen, und entsprechend unbeleckt bei dem Thema. Vielleicht kann mir ja jemand auf die Sprünge helfen, ich schreibe das dann auch gerne als Update dran. Nehmen wir nun als letztes Beispiel die Wirtschaftsrubrik.
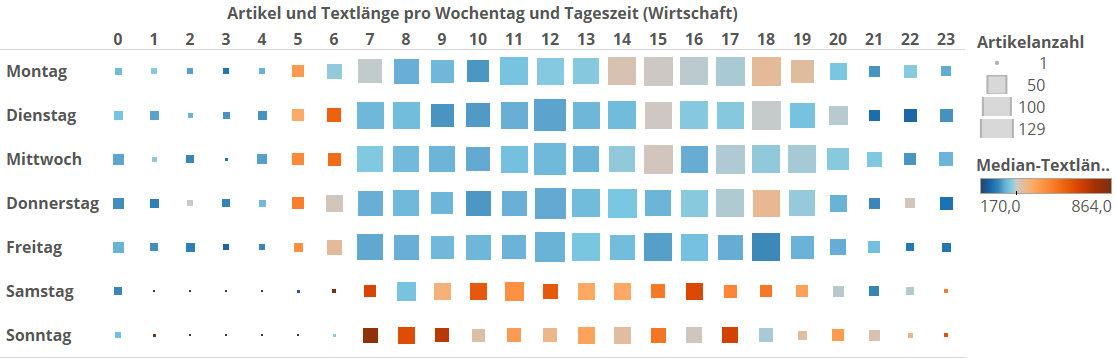
In der Wirtschaftsrubrik ist der eklatante Unterschied zum Standardmuster, dass es Wochenends ganztags viele lange Artikel gibt, und nicht nur morgens.
Ein kurzer Hintergrund: Was ist DataScience?
Die Methodiken des Datensatz-Erforschens heißen neudeutsch DataScience und sind im Moment sehr gehypetes Gebiet im Umfeld der Informatik. Da ich mich seit 2005 mit Machine Learning beschäftige, habe ich das schon gemacht, bevor es cool war, und interessiere mich entsprechend dafür. DataScience heißt, kreativ an einen zunächst unbekannten Datensatz heranzugehen. Diesen erschließen, Wissen daraus erzeugen, verschiedenste Auswertungen durchführen und die Ergebnisse so aufbereiten und kommunizieren, dass sie auch jemand verstehen kann, der kein Informatiker ist. Und vor allem: So dass auch jemand neue Aspekte, Fragestellungen und Inspirationen beitragen kann, der kein Informatiker ist. Visualisierungen sind dabei enorm wichtig – denn unsere Augen sind die einzige echte Breitbandleitung zum Gehirn, die wir haben. Alles andere ist Modemgeschwindigkeit.
DataScience ist vor allem auch: Kreativ Sachen aus Datensätzen herauslesen, für die die Datensätze nie gedacht waren. Das ist die wahre Kunst. Und die werden wir im Verlauf dieses und der nächsten Artikel Hands-On lernen.
Wie geht es weiter?
So, ich denke, das war für einen ersten Einblick erstmal ganz gut. Wir haben heute grob behandelt, was DataScience ist, und ich habe mein Vorhaben umrissen, mit DataScience-Methodiken einmal eines unserer größten Nachrichtenportale zu durchleuchten. Ganz kleinschrittig haben wir dann geguckt, was man aus Veröffentlichungszeiten, Rubrik und Textlänge bereits herauslesen kann – und vor allem, wie. Und was passiert weiter?
Nach und nach werden die Auswertungsverfahren hier komplizierter werden und vor allem werden viele weitere Merkmale hinzukommen. Wir werden mehr und mehr über SpiegelOnline entdecken und mit bunten Bildchen garnieren.
Ich kann jetzt schon versprechen, dass es ein paar Überraschungen geben wird. Wenn ihr eine Intuition für Datensätze und deren Auswertung habt, oder gar SpiegelOnline-Redakteur seid, werdet ihr in diesem Artikel wahrscheinlich schon eine grobe Vorstellung bekommen haben, was man mit meinem Datensatz so alles anstellen kann.
Ich freu mich drauf!